

数据之于人工智能就如同燃油之于汽车。人工智能模型开发需要输入海量训练数据,单个样本数据集大小即可达到上百GB,如果采用人工拷贝、搬运数据,不仅费时费力,而且存在数据冲突和数据安全风险,在这种情况下,数据对于AI模型训练来说不是“加油”,而是成为模型开发的瓶颈,影响企业AI应用效率。浪潮AIStation企业级人工智能开发平台,可以一站式进行AI模型开发和部署,在数据管理方面可实现集中管理,兼顾读取速度与安全性,打破数据孤岛和IO瓶颈,帮助用户获得200%-300%的开发效率提升。
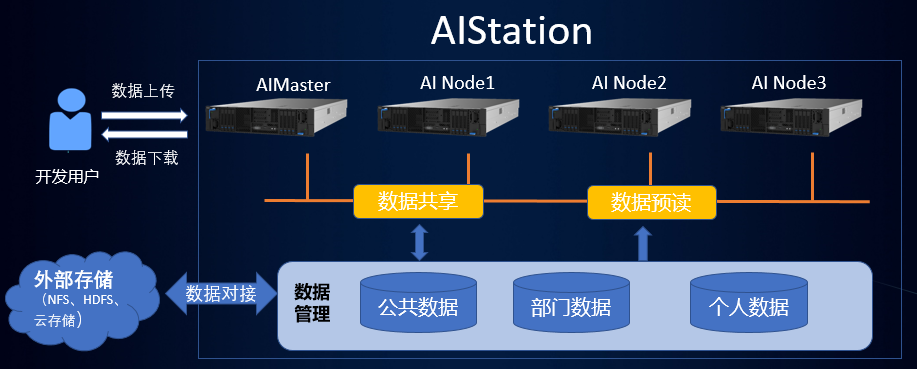
浪潮AIStation集中管理数据
可视化&多种数据访问方式 兼顾便捷与数据安全
AI开发涉及的数据包括样本数据集、模型文件等,种类非常多,格式和特性各异。此外,AI开发需要企业内各业务组的协同工作,必须有完善的数据管理机制保障数据的流通和共享,否则就会存在数据冗余、版本冲突、权限控制等方面的问题。
AIStation平台内置数据管理模块,可无缝对接各类存储系统,提供可视化界面对数据进行集中管理。开发人员可在数据管理界面快速上传数据,并通过目录挂载的方式实时调取数据,进行数据预处理、模型开发、模型调试等工作。训练结束后,用户可按需保存、上传、共享模型文件。
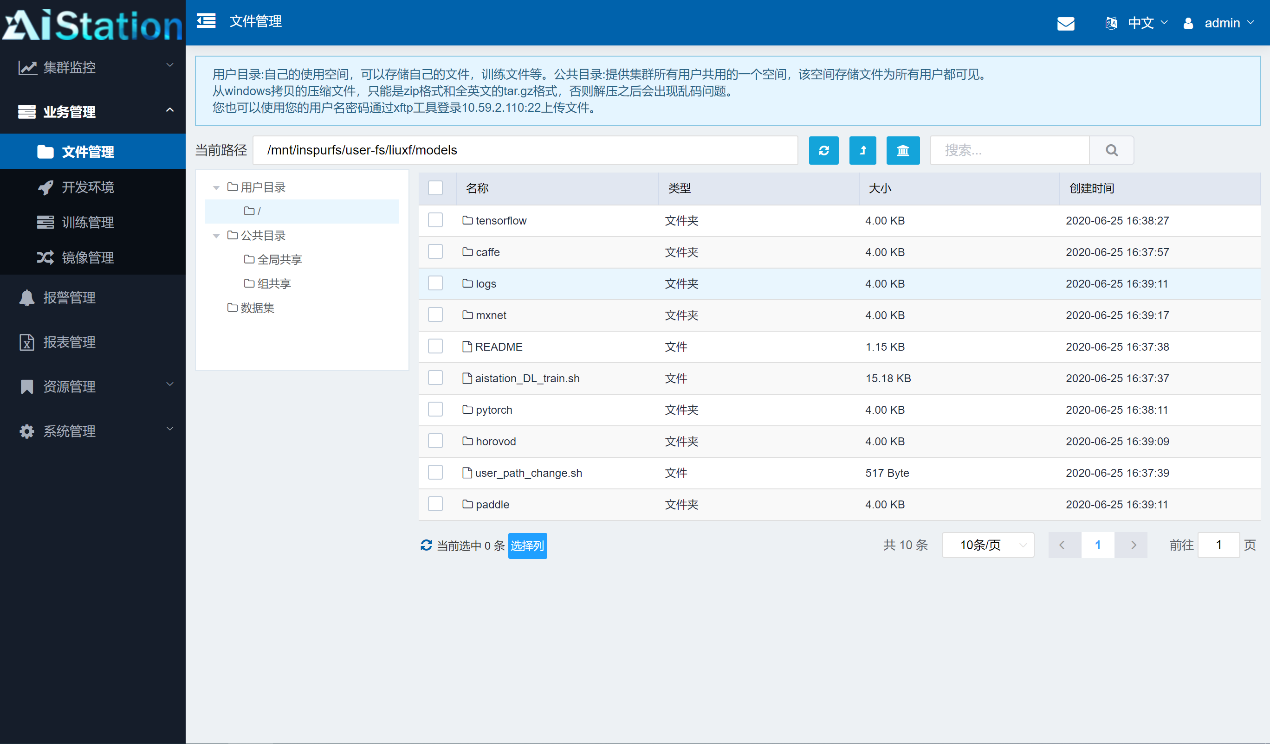
浪潮人工智能开发平台AIStation数据管理界面
AIStation提供了个人数据、组内数据和公共数据三种数据访问控制方式,满足了企业内部用户数据隔离与共享的需求。并为每个用户和部门创建了不同的命名空间,以及相应的权限控制功能,让开发人员能够根据业务需求灵活共享数据,并保障数据安全。
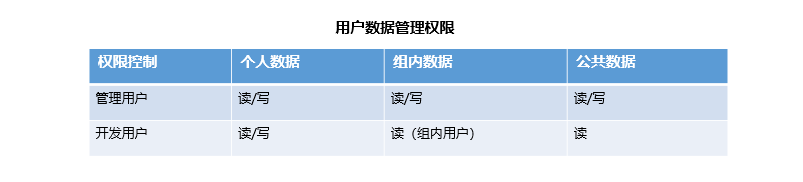
AIStation提供三种数据访问方式
数据缓存加速,训练效率提升200%-300%
数据输入输出是影响模型训练周期的重要因素。即使GPU性能再强,也需要高性能的输入/输出系统不断的将数据传送给GPU进行运算。输入的样本数据通常是小文件,并且在迭代过程中会随机读取样本进行训练,产生较高的随机读负载。而AI企业一般使用共享存储或者分布式存储管理数据,计算节点通过网络挂载的方式访问存储数据,这样即便使用万兆网络或者Infiniband网络,也有可能存在数据带宽不能满足GPU计算输入的问题。

数据I/O成为计算瓶颈
AIStation综合考虑AI计算对数据I/O的需求以及企业内部的实际场景,通过数据缓存机制满足高性能计算需求,可让模型训练效率获得200%-300%的提升,缩短模型开发周期。
AIStation可在各计算节点划分数据缓存区域,用来临时存放用户训练所需的样本数据,通过本地SSD盘的高速I/O降低数据读写延迟。此外,AIStation会根据节点的数据缓存情况自动调度训练任务,从而避免训练数据的重复下载,节省数据加载时间,加速模型训练进度。并且支持数据自动下载和数据缓存管理。
安全沙箱技术,为数据隐私护航
数据安全对企业AI开发至关重要,一套优秀的数据管理解决方案必须能够保证数据安全,确保数据不会发生增加、修改、丢失和泄露等。
AIStation采用安全沙箱技术,将企业数据存储区域与个人数据区分开,保证数据隐私安全。管理员可以设置数据下载权限,限制指定用户或用户组的下载功能,使涉密数据只能在平台内部使用,保障企业数据的安全性。
此外,AIStation可实现数据自动多副本备份,降低宕机等原因导致的系统中断对AI开发的影响。
浪潮AIStation平台针对AI开发中的数据管理问题输出整体解决方案,可以帮助企业用户建立稳定高性能的数据管理机制,消除数据安全、数据冲突、带宽延时等问题,让模型训练效率获得200%-300%的提升,显著提升企业AI研发效率。
除了数据,AIStation还能高效管理计算资源、开发环境,帮助AI用户提高计算资源利用率,秒级构建开发环境,加速AI研发创新进程。

