
事情从未变得如此糟糕,因为工程师们努力降低芯片功耗。数据中心片上系统 (SoC) 设计在性能方面始终仅次于超级计算机处理器,但它们通常每平方厘米仅消耗约 200 至 400 瓦特。装在口袋里的智能手机内的芯片通常会消耗大约5 瓦的功率。
尽管如此,虽然计算机芯片不会在你的口袋里烧出一个洞(尽管它们会变得足够热来煎鸡蛋),但它们仍然需要大量电流来运行我们每天使用的应用程序。以数据中心 SoC 为例:平均而言,为其晶体管提供大约 1 到 2 伏的电压需要消耗 200 W功率,这意味着该芯片从为其供电的稳压器中吸收了 100 到 200 安培的电流。作为对比,普通冰箱仅消耗 6 A 电流。高端手机消耗的功率仅为数据中心 SoC 的十分之一,但即便如此,电流仍约为 10-20 A。那就意味着你的口袋里最多可放三台冰箱!
向数十亿晶体管提供电流正迅速成为高性能 SoC 设计的主要瓶颈之一。随着晶体管不断变得更小,为它们提供电流的互连必须更加紧密并做得更加精细,这会增加电阻并降低功耗。
如果这个不能解决,我们的芯片不能继续。换而言之,如果电子进出芯片上设备的方式没有大的改变,我们制造多小的晶体管都于事无补。

幸运的是,我们有一个很有前途的解决方案:我们可以使用长期以来被忽视的硅片的一面。
电子必须走很长一段路才能从产生它们的源头到达用它们计算的晶体管。
在大多数电子产品中,它们沿着印刷电路板的铜迹线进入容纳 SoC 的封装,通过将芯片连接到封装的焊球,然后通过片上互连连接到晶体管本身。真正重要的是最后一个阶段。
要了解原因,才能有助于了解芯片的制造方式。
SoC 最初是一块裸露的高质量晶体硅。我们首先在该硅片的最顶部制作一层晶体管。接下来,我们用金属互连将它们连接在一起,形成具有有用计算功能的电路。这些互连形成在称为堆栈的层中,可能需要 10 到 20 层的堆栈才能为当今芯片上的数十亿个晶体管提供电力和数据。
最靠近硅晶体管的那些层又薄又小,以便连接到微小的晶体管,但是随着您在堆栈中上升到更高级别,它们的尺寸会增加。正是这些具有更广泛互连的级别更擅长提供功率,因为它们具有较小的电阻。
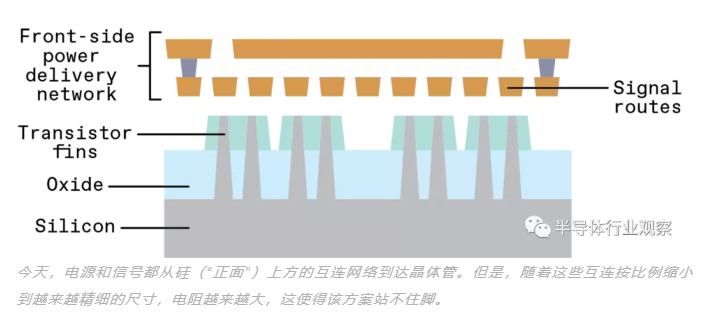
然后,您可以看到,为电路供电的金属——供电网络 (power delivery network:PDN)——位于晶体管的顶部。我们将此称为前端供电。您还可以看到,电力网络不可避免地与传输信号的电线网络竞争空间,因为它们共享同一组铜线资源。
为了从 SoC 获得电源和信号,我们通常将最上层的金属(距离晶体管最远)连接到芯片封装中的焊球(也称为凸点)。因此,为了让电子到达任何晶体管以做有用的工作,它们必须穿过 10 到 20 层越来越窄和曲折的金属,直到它们最终能够挤进最后一层局部导线。
这种分配电力的方式从根本上看是有损的。因为在沿途的每个阶段,都会损失一些电力,而一些电力必须用于控制输送本身。在当今的 SoC 中,设计人员的预算通常允许损耗导致封装和晶体管之间的电压降低 10%。因此,如果我们在供电网络中达到 90% 或更高的总效率,我们的设计就走在正确的轨道上。
从历史上看,这样的效率可以通过良好的工程实现——有些人甚至可能会说,与我们今天面临的挑战相比,这很容易。在当今的电子产品中,SoC 设计人员不仅必须管理不断增加的功率密度,而且还要处理随着每一代产品的出现而以急剧加速的速度失去功率的互连。
您可以设计一个效率高达传统前端网络七倍的后端供电网络。
损耗的增加与我们如何制造纳米线有关。这个过程及其伴随的材料可以追溯到 1997 年左右,当时 IBM 开始用铜而不是铝制造互连,行业随之发生转变。在那之前,铝线一直是优良的导体,但沿着摩尔定律曲线再走几步,它们的电阻很快就会变得太高,变得不可靠。
在现代 IC 规模下,铜的导电性更强。但是,一旦互连宽度缩小到 100 纳米以下,即使是铜的电阻也开始出现问题。今天,最小的制造互连线约为20 纳米,因此电阻现在是一个紧迫的问题。
它有助于将互连中的电子描绘成台球桌上的全套球(It helps to picture the electrons in an interconnect as a full set of balls on a billiards table.
)。现在想象一下把它们从桌子的一端推到另一端。一些会在途中相互碰撞和弹跳,但大多数会沿着直线行驶。现在考虑将桌子缩小一半——你会得到更多的碰撞,球会移动得更慢。接下来,再次缩小它并将台球的数量增加十倍,您就处于芯片制造商现在面临的情况。真正的电子不一定会碰撞,但它们彼此靠得足够近,以施加散射力,破坏通过导线的流动。在纳米尺度上,这会导致导线电阻大大增加,从而导致显着的功率传输损耗。
增加电阻并不是一个新的挑战,但我们现在看到的每个后续工艺节点的增加幅度是前所未有的。此外,管理这种增长的传统方法不再是一种选择,因为纳米级的制造规则施加了如此多的限制。我们可以任意增加某些电线的宽度以对抗不断增加的电阻的日子已经一去不复返了。现在设计人员必须坚持某些特定的线宽,否则芯片可能无法制造。因此,该行业面临互连电阻较高和芯片上的空间较小的双重问题。
还有另一种方法:我们可以利用位于晶体管下方的“空”(empty)硅。在作者 Beyne 和 Zografos 工作的 Imec,他们开创了一种称为“埋入式电源轨”(buried power rails)或 BPR的制造概念。该技术在晶体管下方而不是上方建立电源连接,目的是创建更粗、电阻更小的轨道,并为晶体管层上方的信号传输互连腾出空间。
要构建 BPR,您首先必须在晶体管下方挖出深沟槽,然后用金属填充它们。您必须在自己制作晶体管之前执行此操作。所以金属的选择很重要。这种金属需要承受用于制造高质量晶体管的加工步骤,其温度可达 1,000 °C。在那个温度下,铜会熔化,熔化的铜会污染整个芯片。因此,我们对熔点较高的钌和钨进行了试验。
由于晶体管下方有如此多的未使用空间,您可以将 BPR 沟槽做得又宽又深,这非常适合输送电力。与直接位于晶体管顶部的薄金属层相比,BPR 的电阻可以是其 1/20 到 1/30。这意味着 BPR 将有效地允许您为晶体管提供更多功率。
此外,通过将电源轨从晶体管的顶部移开,您可以为信号传输互连腾出空间。这些互连形成基本电路“单元”——最小的电路单元,例如 SRAM 存储器位单元或我们用来组成更复杂电路的简单逻辑。通过使用我们腾出的空间,我们可以将这些单元缩小16% 或更多,这最终可以转化为每个芯片上更多的晶体管。即使特征尺寸保持不变,我们仍然会进一步推动摩尔定律。
不幸的是,似乎仅埋葬本地电源轨是不够的。您仍然必须从芯片的顶部向下向这些轨道输送电源,这将降低效率和一些电压损失。
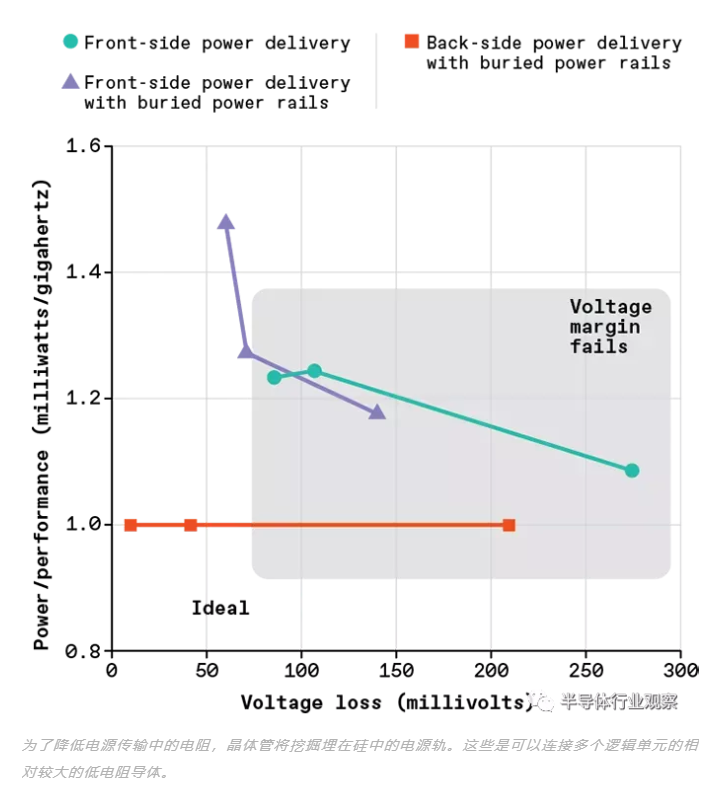
Arm 的研究人员 Cline 和 Prasad在他们的一个 CPU 上运行了一个模拟,发现 BPR 本身可以让你构建一个比普通前端供电网络效率高 40% 的供电网络。但他们还发现,即使您使用 BPR 与前端供电,传输到晶体管的总电压也不够高,无法维持 CPU 的高性能运行。
幸运的是,Imec 同时开发了一种补充解决方案,以进一步改善供电。那就是将整个供电网络从芯片的正面移动到背面。这种解决方案称为“背面供电”(back-side power delivery),或更一般地称为“背面金属化”(back-side metallization)。它涉及将晶体管下方的硅减薄至 500 nm 或更小,此时您可以创建纳米尺寸的“硅通孔”或纳米 TSV。这些是垂直互连,可以通过硅的背面连接到埋入轨道的底部,就像数百个微型矿井一样。一旦在晶体管和 BPR 下方创建了纳米 TSV,你可以在芯片背面放置额外的金属层,以完成一个完整的供电网络。
扩展我们早期的模拟,我们在 Arm 的设计中发现,只有两层厚的背面金属就足以完成这项工作。只要您可以将纳米 TSV 彼此间隔的距离小于 2 微米,您就可以设计出效率是带有埋入式电源轨的正面 PDN 的四倍和传统 PDN 效率的七倍的背面 PDN前端 PDN。
背面 PDN 具有与信号网络物理分离的额外优势,因此两个网络不再竞争相同的金属层资源。每个人都有更多的空间。这也意味着金属层特性不再需要在电源路径偏好(厚而宽,低电阻)和信号路径偏好(薄而窄,以便他们可以用密集封装的晶体管制作电路)之间进行折衷。您可以同时调整用于电源布线的背面金属层和用于信号布线的正面金属层,并获得两全其美的效果。

在 Arm 的设计中,我们发现对于传统的前端 PDN 和带有埋入式电源轨的前端 PDN,我们不得不牺牲设计性能。但是通过背面 PDN,CPU 能够实现高频率并提供高效的电力传输。
当然,您可能想知道如何在这种方案中从封装获得信号和电源到芯片。纳米 TSV 也是这里的关键。它们可用于将所有输入和输出信号从芯片的正面传输到背面。这样,电源和 I/O 信号都可以连接到放置在背面的焊球上。
模拟研究是一个很好的开始,它们展示了具有 BPR 的后端 PDN 的 CPU 设计级潜力。但是,要将这些技术应用于大批量制造,还有很长的路要走。仍然存在需要解决的重大材料和制造挑战。用于 BPR 和纳米 TSV 的金属材料的最佳选择对可制造性和电气效率至关重要。此外,BPR 和纳米 TSV 所需的高纵横比(深但细)沟槽非常难以制造。在硅基板上可靠地蚀刻紧密间隔、深而窄的特征并用金属填充它们对于芯片制造来说是相对较新的,并且仍然是该行业正在努力解决的问题。
此外,电池供电的 SoC,如手机和其他功率受限设计中的 SoC,已经拥有比我们目前讨论的更复杂的供电网络。现代电力输送将芯片分成多个电源域,这些电源域可以在不同电压下运行,甚至可以完全关闭以节省电力。
因此,背面 PDN 和 BPR 最终要做的不仅仅是有效地传输电子。他们将不得不精确控制电子的去向以及到达那里的电子数量。当涉及到芯片级电源设计时,芯片设计人员不会想退后几步。因此,我们必须同时优化设计和制造,以确保 BPR 和背面 PDN 优于——或者至少兼容——我们今天使用的节能 IC 技术。
计算的未来取决于这些新的制造技术。无论您是担心数据中心的冷却费用还是每天为智能手机充电的次数,功耗都是至关重要的。随着我们继续缩小晶体管和 IC 的尺寸,提供功率成为一个重大的片上挑战。如果工程师能够克服随之而来的复杂性,BPR 和背面 PDN 可能会很好地应对这一挑战。

